As I’m sure is clear for the title, today we’re talking about OIT or Order-Independent Transparency.
I’ve been working on transparent object support for Shade for the past few weeks. Doing opaque stuff is easy, doing alpha-tested transparencies is a bit trickier, but no big deal. Transparent objects however… hard stuff.
First of all, to help us visualize the problem, let’s consider how we draw non-transparent stuff. Let’s use a toy example of 3 walls of different height and an observer looking at them from head-on

If the walls A,B and C are fully opaque (that is, non-transparent), we can draw the walls in any order and use depth buffer (also known as Z buffer) to keep track of which one should be drawn to the screen. If we draw A first, say it has depth of 0.1 (normalized distance to camera), when we try to draw B at depth 0.2 - the shader will immediately know that 0.2 > 0.1, and therefore the pixel will be “discarded”, that is - it will not be written. When we draw C at depth 0.3 - same thing as with B - discarded.
If we draw C first, our depth buffer will have value 0.3, then we draw B - it will overwrite C as depth is smaller ( 0.2 < 0.3 ) so we will overwrite C’s color with B, then finally A will overwrite B because its depth is even smaller.
This is not terribly original stuff, we’ve been doing depth-testing for donkey’s years.
Transparency
I’m going to use word “fragment” to refer to a pixel shaded by a material shader from now.
With transparencies things are not as clear. We can’t use a depth buffer, because there isn’t one final color, in fact - all objects will contribute to the final color, so in a sense - we could use a depth buffer, but we’d need as many depth buffers as there are planes, or in our case - triangles. That’s not something practical, so depth buffer is pretty much useless. Most techniques that do transparency explicily disable depth writing. We can still read depth buffer that was produced by opaque fragments to quickly discard transparent fragment, but we don’t write to depth buffer. In three.js it’s the corresponding controls are:
Material.depthTest and Material.depthWrite, pretty descriptive names, once you know what you’re dealing with.
So, if we don’t write depth, how do we decide what should be visible? Well, there’s alpha (opacity) value that a fragment produces, and a vey simple formula where S is the fragment we’re drawing and D is the current color in the render texture we’re drawing to:
R = S.rgb*S.a + D.rgb*(1.0 - S.a)
In fact, this is so common that it’s called “normal blending” in a lot of places, including three.js, where it’s the value of Material.blending which defaults to NormalBlending. Other commonly used name is “Alpha Blending”.
Alpha blending is neat, but it has a massive flaw - it’s non-commutative, in other words - order of blending matters. To illustrate, here are two circles with 0.7 alpha (30% transparency)

Here’s what happens if we overlap the circles with green on top:

And here’s the other way around:

Hopefully it’s clear that the blend produces an entirely different color depending on the order.
Now, you’re probably a clever reader and shouting “aha! just sort the objects!” at this point. And indeed, that’s a good strategy, we can sort objects by distance and get the right blend… Except, only if that’s actually doable. If you have two circles like this - it’s all good an well, but in 3d we typically have more complex shapes than this. Consider the following example of just two intersecting rectangles:

What you will see is something like this

or this

depending on how you sort the objects, because the part of each rectangle that’s closest to the camera is about the same distance away from the camera, so there’s no clear winner. Also - both of these are wrong, what you should get is this instead:

Think back to the diagram with the overlapping circles if you need to convince yourself that this is true.
So.. How do we get this? We can sort all triangles, except, if you believe me so far, you’ll see that the same issue happens with two intersecting triangles the same way it does with two rectangles.
If order matters, and sorting objects and triangles is not the solution, what can we do?
There are 3 broad categories of solutions:
- Slice the scene along the camera view and draw one slice at a time on top of another, this is your “depth peeling” method. There’s more involved there, but that’s the basics.
- Keep multiple layers of transparency for each pixel. There are 2 broad variants here, one with fixed size where you have, say 4 layers and use some formula to decide which layer a fragment should be drawn to and what blendining to use. The second variant is unbounded, where you store all layers, typically as a linked list that can be sorted during or after the main pass.
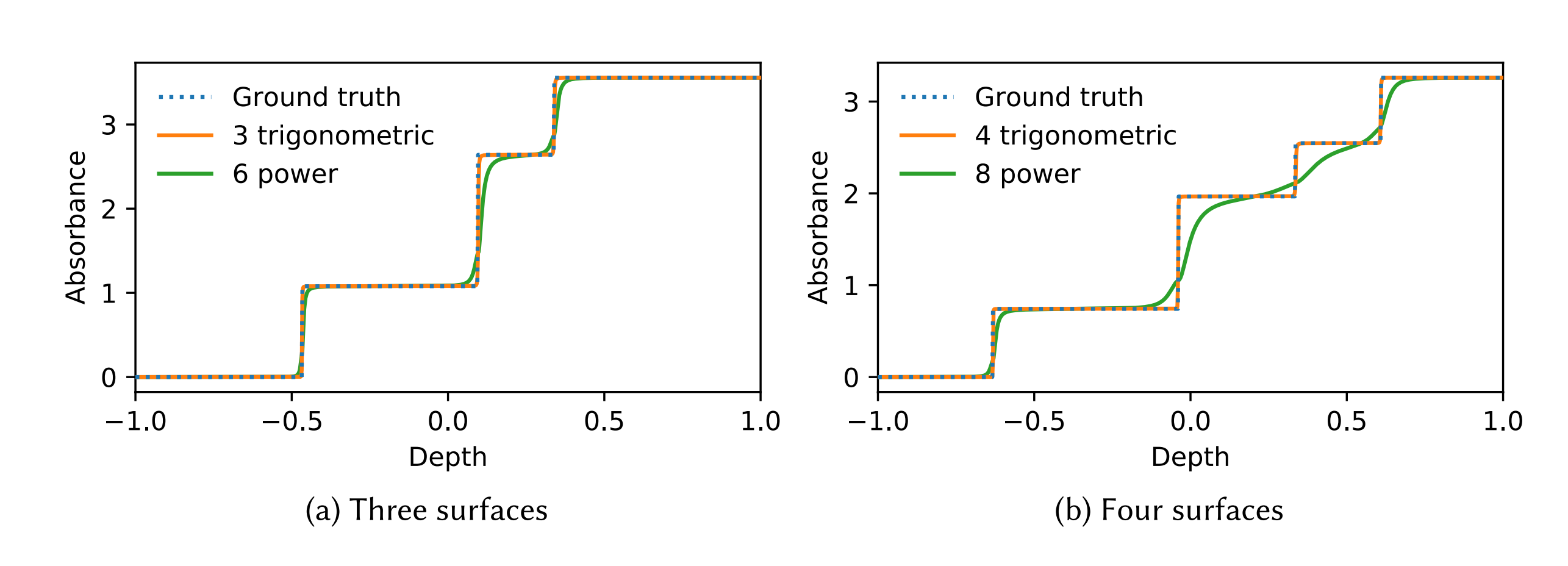
- Estimation and heuristics. Even here we have 2 borad categories, first is discrete, we generate a random number to decide if the pixel should be drawn or not, you end up with a dither of some kind as a result. The second variant is continuous which uses estimation or statistics, for example, you can construct a curve such as
Ax^2 + Bx + Cand fit it as you draw, to represent something likeabsorption/depth.
For those interested, three.js implements discrete variant of 3rd category:

Here’s what that looks like if you enable tempotal accumulation

pretty good, even if still a bit noisy.
It would be remiss of me not to mention @pailhead and his Depth peel and transparency implementation, link:
Order-Independence
Going a bit further with classification, techniques that do not rely on drawing object/triangles in a specific order are broadly called “Order-Independent”, even if there’s a bit of sorting involved somewhere along the way else-where.
This brings us to the reason I’m writing this article. I’ve been looking for a suitable technique for Shade, here’s what I considered:
- Sort objects.
- Sort triangles.
- Use hash-based technique (same as the variant that three.js impements)
I was unhappy with sorting, as it needs to be done on the GPU, and sorting, even on the GPU, is a massive pain, it’s either very hard or requires a large number of passes, and in all cases it’s not fast.
I didn’t like hash-based implementation, despite writing it - it was a bit too noisy for my liking. I have a better TAA implementation, so the amount of noise was much lower than three.js, but it was still very noticeable. One point to mention here, for those that might be interested - you can get pretty good spatial and tempotal stability with the technique, there are a number of good papers out there (sorry, don’t remember them, but you can find a bunch with google).
So as I was finishing up with alpha-tested transparencies, I stumbled on a mention of transparency implementation in Alan Wake 2, at Remedy’s REAC presentation on meshlet rendering. They went with MBOIT (Moment-Based Order-Independent Transparency), which belongs in the 3rd category of techniques, and is a not-so-distant cousin of Variance Shadow Maps (which, again, three.js implements ). But where variance techniques require 2 moments, MBOIT goes further and extends the technique to N number of moments. With the most common one, as far as I can tell, being the 4-moment one.
MBOIT
And here we are, after more than a week of pain, I’m at the stage where I have something to show, so I thought I’d write up a bit more on the topic for the uninitiated and hopefully provide a gentle introduction into the topic.
My implementation uses 3 passes:
- generation of moments (geometry pass)
- resolution of moments (geometry pass)
- compositing of transparency (image pass)
The first pass is quite cheap as I’m reading just alpha-related parts of the material and no actual shading is performed. Resolution of moments requires full shading, and last pass is similar to post-process, where we just smash two images together with a bit of math.
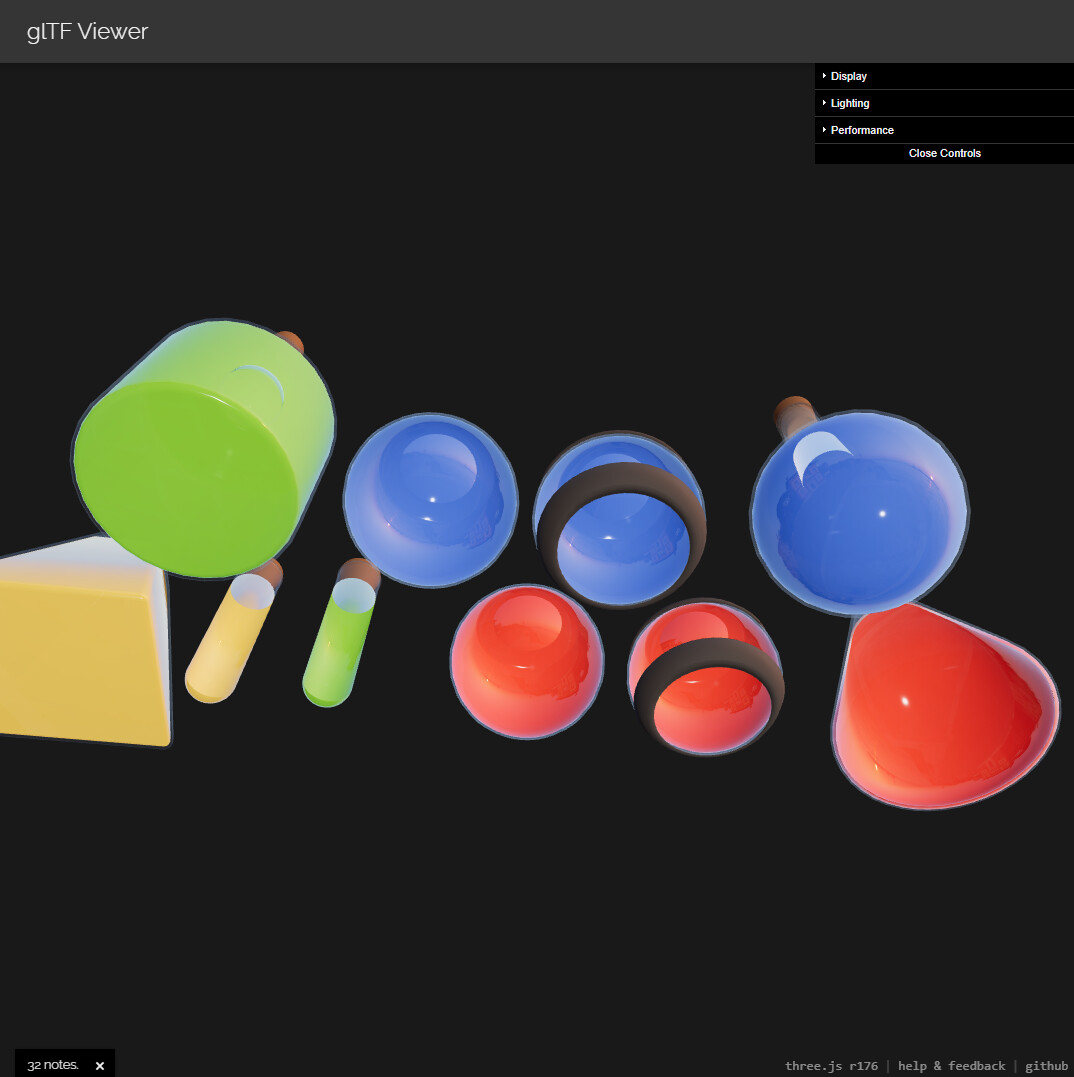
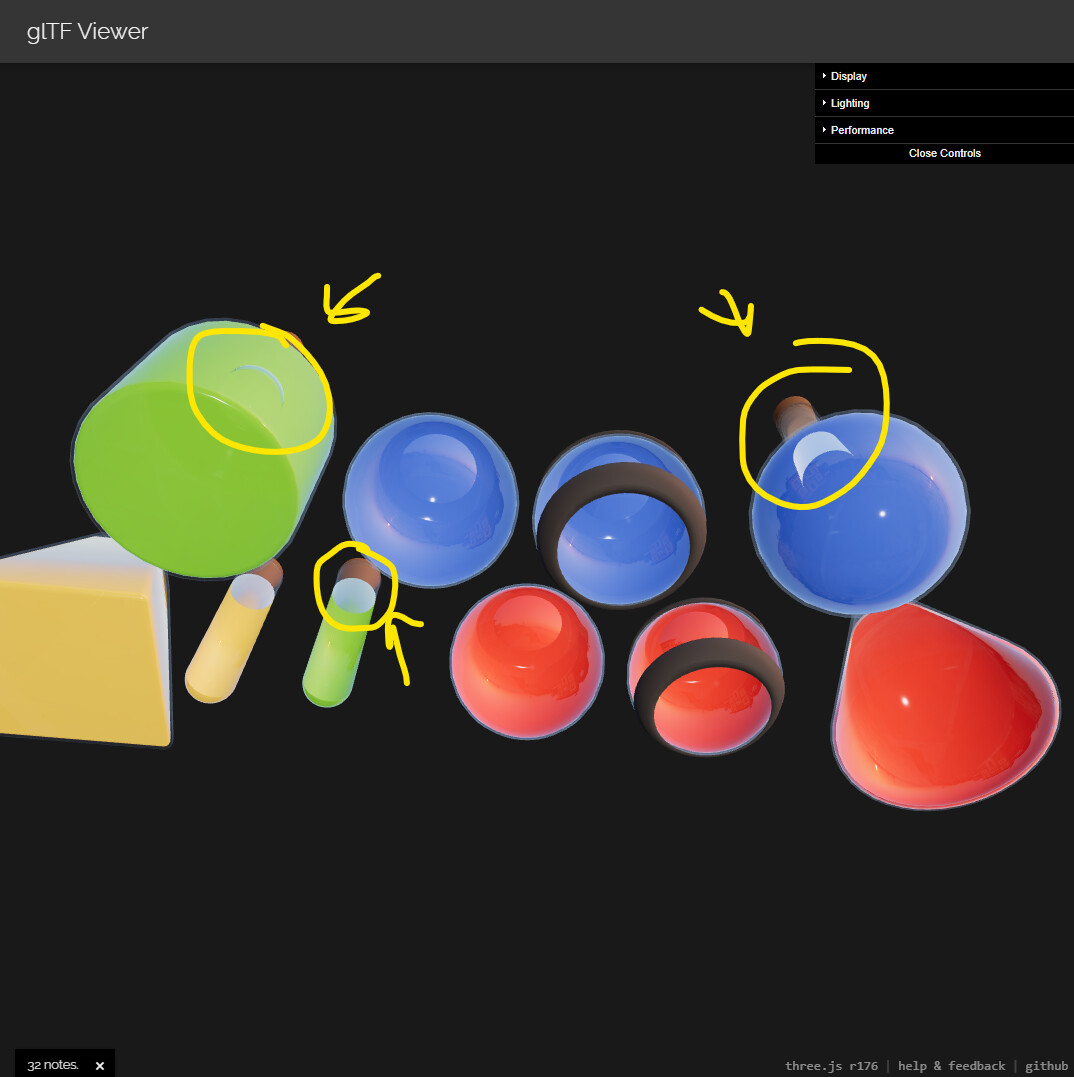
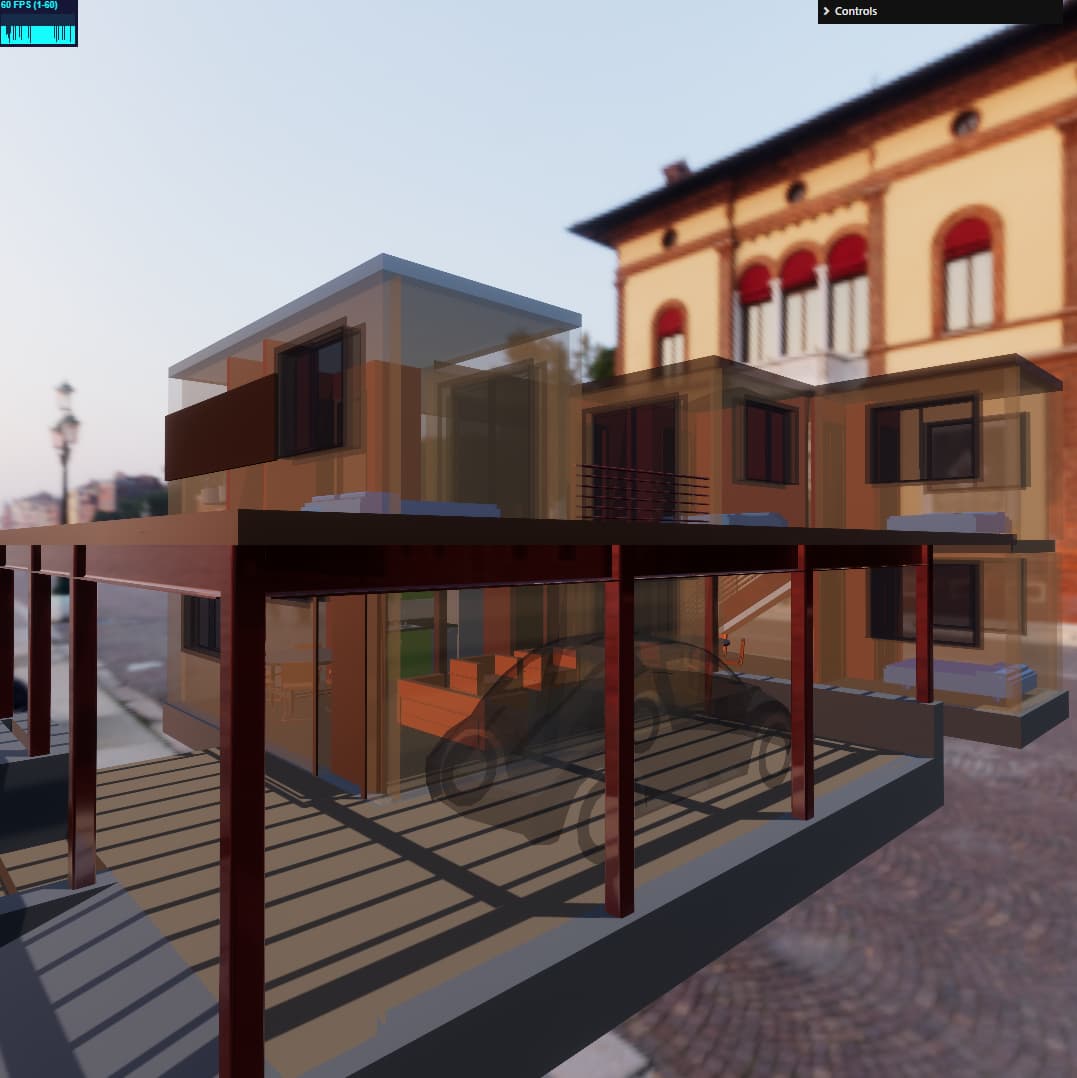
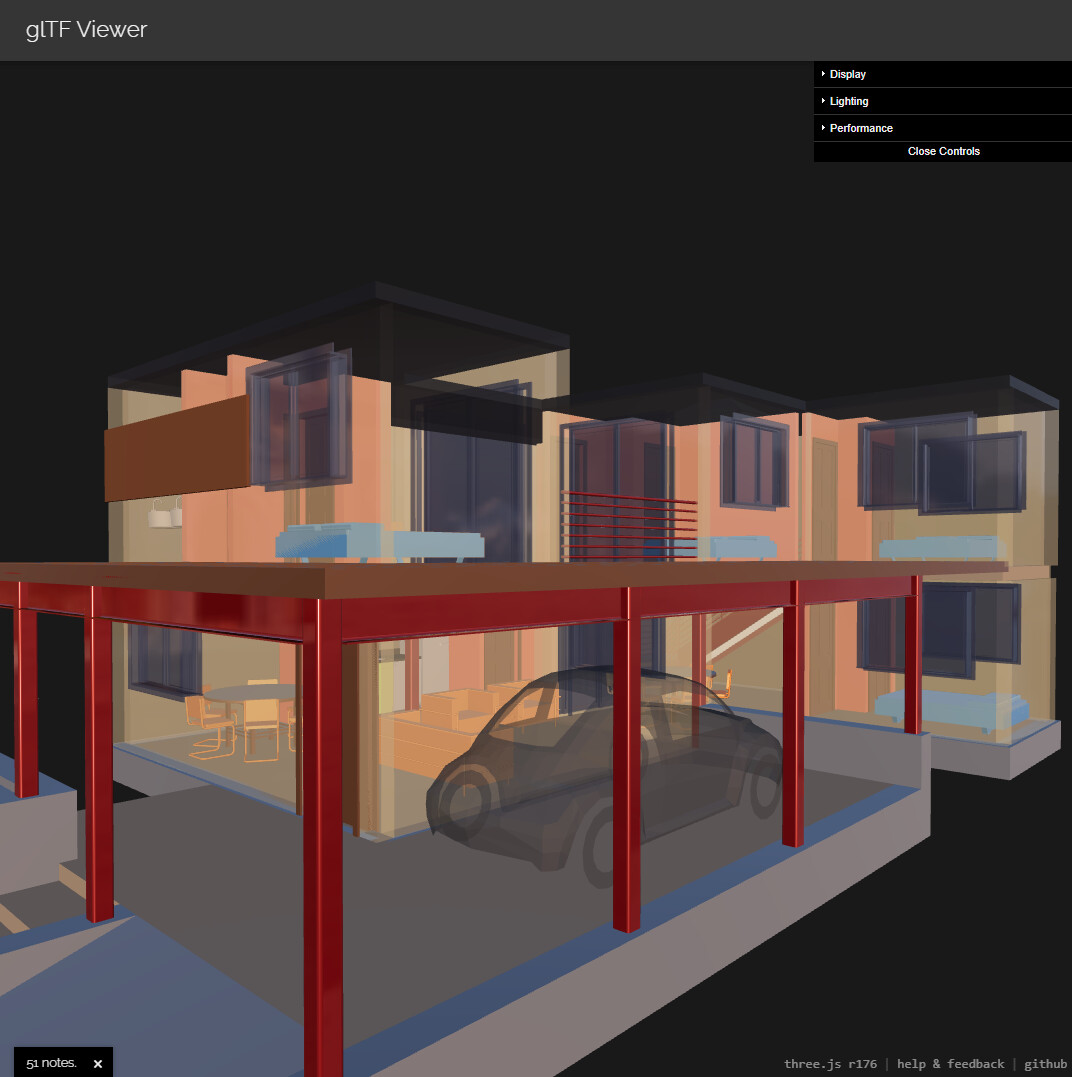
Here are a few screenshots of shade vs three.js to highlight difference

Shade

three.js


Quite often this stuff doesn’t matter much. You have a t-shirt configurator say - you don’t even need transparencies. Or you have an archviz usecase with some building, you want windows to look right - just make sure that each window is a separate object and it will mostly look right.
Where transparencies start to be more critical are usecases with particle effects, non-planar glass (such as bottles or vases) and, of course, water.
As for me, Shade is intended to be a turnkey solution. I don’t want to force the user to adapt their content as much as possible, so graceful handling of transparencies in all usecases is an important point for me.